I worked on analyzing political affiliations based on plain text, which is pretty similar to judging whether a given article is part of fake news or not. The main objective behind this exercise was to generate some sort of labelled data to train an ML model with. Fake News detection is a hard problem and it becomes harder if you don’t have a region-specific fake news dataset. In this blog-post, we try to find out the groups or communities using their twitter characteristics like retweets and mentions and constructing a network out of it. I analyze the results I get and will try to make some sense of the data we have.
Gathering Data
The main task in our case is gathering data, I do so by writing a MultiThreaded Tweet crawler which helped me crawl roughly 50 million tweets in roughly 5 days. You can check out the repository and do some crawling for fun. The data was stored in a PostgreSQL database which was also the primary data dump.
Software Used
I used my HomeLab to crawl all this data.
- The first thing you need to do is set up PostgreSQL on your computer which you’ll use for keeping crawled data. There are two settings you should be careful about while configuring the service. First, move the data directory to the disk you’ll use for storage. Postgres by default stores the data in /var directory which can be a problem if you have your root partition on a small-capacity SSD. Also, make sure you can access the database over the network. It becomes way easier to work with the data on your local system using an IDE like DataGrip
- The second thing is writing a Twitter Crawler, I use the official API along with Tweepy library to crawl data. I’ve made the code generic enough so that anyone can download it and run using a simple configuration file. You can clone this repository and edit the configuration file. You can add the handles you want to crawl in the handles.txt file. You can update the handles needed to crawl in the next layer using the -r option.
- It would make working with data extremely easier if you process data on the server itself. To do this there is no better tool than Jupyter Notebooks and Jupyter Lab offers the same features with many additional features. You can install it easily using pip. Once you install it, change some parameters in the configuration file and you are ready to access over the internet.
- For inserting the data in the PostgreSQL database you’ll need a python library. Psycopg2 is the most supported library out there and it’s very easy to use
Once everything is set up correctly, you can launch the TweetCrawler.py file and it will happily chug along crawling twitter handles and storing it in the database. One ‘bug’ is that some of the columns will have curly braces in it. This is mostly due to the way the Psycopg2 library inserts data in the database. You can clean the data using the following SQL command
UPDATE tweets_cleaned as t set retweeted_status_url = TRANSLATE (t.retweeted_status_url,'{}','' );
Once this is done, create index on the ‘tweet_from’ columns to make retrieving and working on the crawled data a bit easier. You can run the following SQL commmand to do that
CREATE INDEX on tweet_cleaned(id);
After these steps you should have data to work with, we will now work on the data we have.
Operating on data
The data I’ve crawled is huge and there is no way to work on it in memory (even after upgrading my main memory to 32gigs). So pandas is out of question. Pandas loads all the data in memory and then performs operations on it, our data size requires us to use more sophisticated solutions which generally are used in case of big data.
Apache spark
Apache spark has a very good dataframe API which can acutally speed up data access and processing. Though it is generally discouraged to use a single node apache spark cluster, I found the advantage of operating directly on data using DF API is significantly greater than loading data in memory and then working on it(which is anyways impossible due to amount of data we have).
Setting up apache spark is fairly straightforward. Complete the setup add the postgres jdbc jar file in the appropriate location and you are good to go. Installing the pyspark package using will make things easier to work with if you prefer python instead of scala like me. The main issue I encountered is that, since the table I’m operating on is a single table with 50 millon rows. There is no parallelism present for the spark to take advantage of which caused ridiculously wait times. Initially these wait times caused a lot of timeouts and changing the settings fixed that. Still the time taken is ridiculous.
To fix this problem I searched for ways to partition the table. Postgres allows you to partition the table using inheritance but in our case the table already exists and there is no easy way to partition table once created. The other option is using pg_partman. I’ll configure the existing tables based on created_at column so that the database is partitioned based on time intervals. This would ideally allow parallel access to the records and should speed up spark access.
Plotting the network
Processing the crawled data in a user interactable form becomes challenging with the scale of data I had. The idea I had was to identify clusters in the twitter network and then do further processing on this information.
Twitter network graph
Constructing the twitter network was done with the NetworkX graphing library in python. I converted the crawled data into list of tuples with one source and one destination node. I kept only the tweets which were retweets for this analysis. In general retweets are a stronger measure of endorsement compared to mentions. I’ve also observed that the more popular personalities’ mentions carry more importance, these personalities rarely retweet. I might scale the edge weights in future keeping this creiteria in mind and do additional processing to get better clutering using gephi’s clustering algorithm.
The function to costruct the graph is pretty simple. The graph we construct is a Directed graph where edge weight is the number of times a user A retweets user B. The python function below does the same simple operation and gives a Directed Graph G.
def create_graph(ls_tup):
G = nx.DiGraph()
for dc in ls_tup:
tfrom=dc['tweet_from']
rt = dc['retweeted_status_user_handle']
if G.has_edge(tfrom,rt):
print(tfrom,rt,G[tfrom][rt]['weight'])
G[tfrom][rt]['weight'] += 1
else:
G.add_edge(tfrom,rt,weight=1)
return(G)
We can do a lot of preprocessing in python itself but I’ve found Gephi to be a much better tool which is easier to use and operate on such large amounts of data. The visualizations are more e engaging and it comes with various plugins to export the network in multiple formats. You can export this Graph easily using GEXF format which can be done using NetworkX library’s write_gexf() function
Gephi processing
Once you get the GEXF file you can run Gephi and import the data into the tool. Before you do that though, make sure you have installed Oracle’s Java version 8. The difference between Oracle Java and the OpenJDK version is day and night. Gephi becomes unusable with OpenJDK if the network is as large as I had. Once installed disable the anti-aliasing in settings to make the renders quicker as well.
Pre-processing
Once you get the data into Gephi you can do some preprocessing, I did the following things to weed out un-important nodes
- Calculate the Eigenvector centrality of the graph. Trim the nodes with Eigenvector Centrality less than say 0.012 (you can adjust this threshold to get better graph)
- Run the modularity algorithm tweaking the parameters to get less number of communities. You can now see major clusters that arise out of data.
- Trim out the clusters with less than say 500 nodes in them. This can be done using the partition count filter in Gephi.
- Run the clustering algorithm once again on this reduced graph. Now you should see the clusters clear enough. In my case, all handles from a particular political party were in the same cluster.
Visualization
Once you have the data the next step is visualizing the data. If you don’t want to visualize, go to the Data tab and select columns of interest in my case that would be the modularity class and export it as CSV or some other format. Visualization in Gephi is pretty confusing if you are new to it. For most of the purposes simply running the ForceAtlas2 layout algorithm will suffice. That’s what I did, I tweaked the parameters of ForceAtlas2 algorithm, I enabled the LinLog Mode, Dissuade hubs and Prevent Overlap parameters. Adjust the scaling and edge weight parameter based on the generated graph. Also increasing iterations will help in case of large networks, though it might take more time depending on the hardware you have.
Once you are happy with the visualization generate it and export it in any format you want. Hot-tip you can use the plugin (Sigma.js Exporter plugin) which will generate a static browser-friendly interactive static. The visualization generated from data looks something like below. Here I’ve trimmed unnecessary data using filters in Gephi. To make the data visualization-friendly you can trim out small communities using partition count filter, you can also trim unimportant nodes from the graph. One way of doing that is removing nodes below a certain weighted degree but this disproportionately reduces nodes in smaller communities. A better way is to use EigenCentrality as a filtering metric, this solves the previous issue and gives a good looking graph. For an interactive version of the below image please visit this link
Using the data to extract relevant information
Once you have the clustering information you need to filter out tweets according to the clusters you have identified, the first step now is to get this clustering data out of Gephi. Getting this data out becomes easier if you export the data directly using a CSV file. The following steps are what I followed
- After running the clustering algorithm i.e getting the modularity classes. Apply the partition count filter and filter by modularity class. Keep only the classes with more than some threshold amount of nodes in it. This will reduce the number of irrelevant communities.
- Go to the Data tab and select the ‘export as a spreadsheet’ option. In the dialogue box only select the id and modularity class columns and save the file.
- Create a separate table which will store this mapping from twitter handle to modularity class mapping. You can create a simple table in Postgres which will have two columns one for twitter_handles and the other will store the modularity class. Copying the CSV data into the table can be done simply by using the following SQL command. Keep in mind that you’ll have to manually remove the heading column if your modularity_class column is of a different datatype like a BIGINT.
COPY cluster_mapping FROM '/path/to/csv/clusters.csv' WITH (FORMAT csv); -
To actually retrieve valuable information like (text,cluster_id) tuples, we’ll need to do retrieve data using SQL JOIN statements. If you have lots of data this JOIN operation becomes very slow, if you don’t have indexes. So we create an index on the twitter_handles column of the new table, we already created an index on the table that has all the tweets.
-
As the number of columns in our case is large it becomes tedious to write the complex SQL statements every time with joins. To make our life more convenient we store these complex queries as VIEWS, once we do that the complex SQL query given below becomes the familiar Select * from view_on_db;. To create the view you just have to prepend “create view non_text_cleaned as “ to the below SQL statement
- Getting this data into Python is tricky. Since my dataset of tweets was very large I decided to upgrade my system Memory to 32 GB. The other way is to use Apache Spark as I’ve noted above. You can still use pandas in python to load using chunking. I read this data into a Jupyter notebook using psycopg2, this was mainly possible because of the RAM upgrade. Running the following SQL statement will fetch the relevant data into a python list. I use INNER join because I don’t want any data which doesn’t lie in the selected Modularity classes.
SELECT t.tweet_from,t.user_mentions_name,t.retweeted_status_user_handle,c.cluster,c.weighted_degree FROM tweets_cleaned AS t INNER JOIN cluster_mapping AS c ON t.tweet_from = c.id ; - Load this data into a pandas data frame using a simple command
df = pd.DataFrame(ls ,columns = ["handle","mentions","retweets","cluster","importance"]) - It is always faster to store this data frame using pickle. You can use the Pandas inbuilt function to_pickle.
from collections import Counter
import string
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from wordcloud import WordCloud
import dask.dataframe as dd
from dask.multiprocessing import get
import networkx as nx
import psycopg2
import psycopg2.extras
def pg_get_conn(database="fakenews", user="fakenews", password="fnd"):
"""Get Postgres connection for fakenews
Returns:
Connection object : returns Post gres connection object
Args:
database (str, optional): Name of database
user (str, optional): Name of User
password (str, optional): Password of user
"""
try:
conn = psycopg2.connect(database=database,
user=user, password=password, host='localhost', port='5432')
return conn
except Exception as e:
print(str(e))
def run_query(query="""Select * from tweets_cleaned""", realDict = False):
print(query)
with pg_get_conn(database="abhishek",user="abhishek",password="vaishu") as conn:
cur = conn.cursor(cursor_factory = psycopg2.extras.RealDictCursor) if realDict else conn.cursor()
cur.execute(query)
ans = cur.fetchall()
return(ans)
def create_graph(ls_tup):
G = nx.DiGraph()
for dc in ls_tup:
tfrom=dc['tweet_from']
rt = dc['retweeted_status_user_handle']
if G.has_edge(tfrom,rt):
G[tfrom][rt]['weight'] += 1
else:
G.add_edge(tfrom,rt,weight=1)
return(G)
def __custom_words_accumulator(series,limit=None):
c = Counter()
for sentence in series:
if sentence:
sent_list = sentence.split(",")
c.update(sent_list)
return c.most_common() if not limit else c.most_common(limit)
def split_list(series,handleBool=True):
handles = []
listNoOfX = []
for groupList in series:
for handle,x in groupList:
handles.append(handle)
listNoOfX.append(x)
if handleBool :
return(handles)
else:
return(listNoOfX)
def get_barcharts(df,column_name="retweets"):
wf = df.groupby("cluster")[column_name].apply(__custom_words_accumulator,limit=50).reset_index()
wf2 = pd.DataFrame({
'cluster_id' : np.repeat(wf['cluster'],50),
'handle': split_list(wf[column_name]),
'noOfX': split_list(wf[column_name],handleBool=False)
})
clusters = wf2.cluster_id.unique()
sns.set(rc={'figure.figsize': (40,10)})
i = 0
f, ax = plt.subplots(len(clusters), 1, figsize=(40, 100))
f.tight_layout(pad=6.0)
for cid in clusters:
g = sns.barplot(x="handle", y="noOfX", hue="cluster_id", data=wf2[wf2.cluster_id==cid],ax=ax[i])
g.set_xticklabels(g.get_xticklabels(), rotation=50, horizontalalignment='right')
i+=1
def plot_word_cloud(word_freq_dict,background_color="white", width=800, height=1000,max_words=300,
figsize=(50, 50), wc_only=False,color_map="viridis"):
"""
Display the Word Cloud using Matplotlib
:param word_freq_dict: Dictionary of word frequencies
:type word_freq_dict: Dict
:return: None
:rtype: None
"""
word_cloud = WordCloud(background_color=background_color, width=width, height=height,
max_words=max_words,colormap=color_map).generate_from_frequencies(frequencies=word_freq_dict)
if wc_only:
return word_cloud
plt.figure(figsize=figsize)
plt.imshow(word_cloud, interpolation='bilinear')
plt.axis("off")
plt.show()
Now that everything is setup we can begin with analysing the data we have. I’ve started with basic analysis using just Pandas to get a good idea about the process. We start by analysing the clusters we have generated. The clusters make sense only if all the handles speak on a particular topic. With some data wrangling in python using Pandas, I’ve managed to plot the top 50 handles in each cluster and plot a bar chart. If you see the Image generated below you can see the clusters clearly correspond the users who speak or are interested in similar areas.
df = pd.read_pickle("pickles/mention_retweet_hastags.pkl")
get_barcharts(df,"mentions")
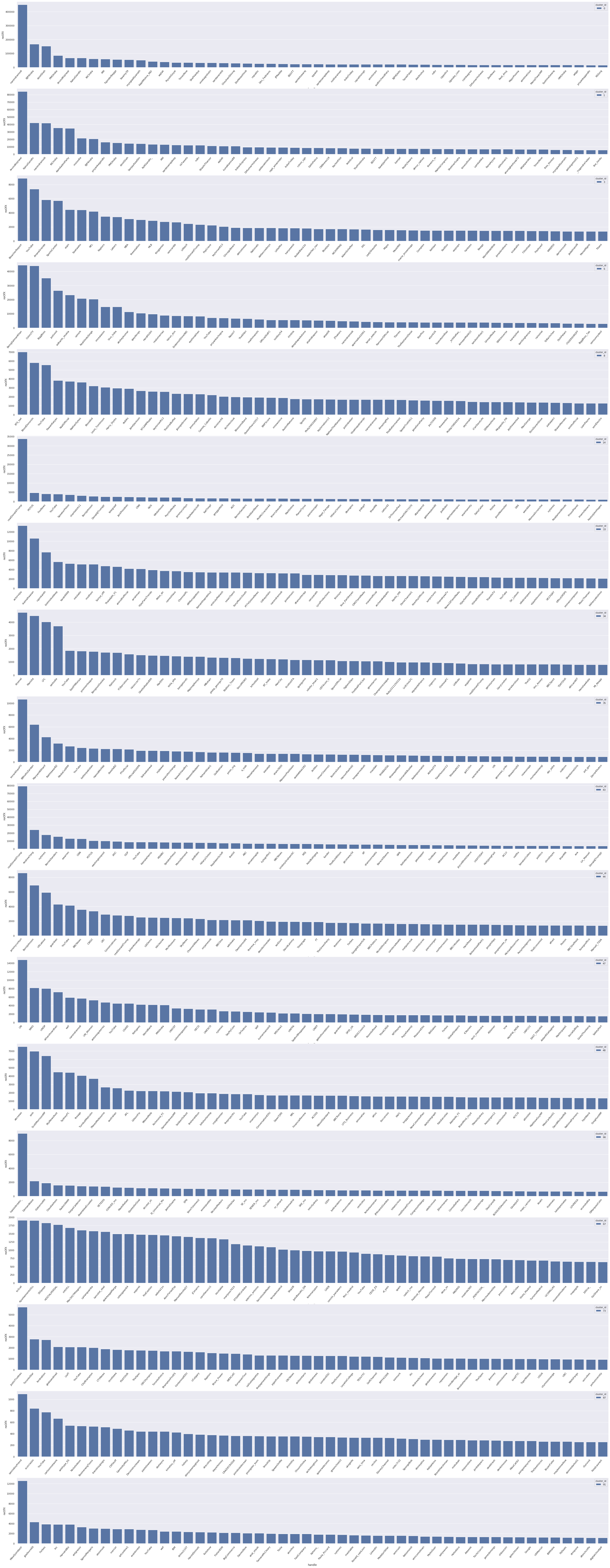
I’ve plotted the mentions in each cluster in the chart above. Why did I choose mentions instead of hashtags or retweets? One important reason was disassociation from the clustering process used in Gephi and this analysis. We have already constructed the graph using retweets, if we again use retweets to see if the clusters generated are homogenous or not, we won’t’ be getting any new information. Looking at the chart we can see that the clusters below have users from a specific group of similar-minded individuals. Below I discuss the characteristics of each cluster.
Clusters
- 0 -> If you see the first bar graph. you can see the top 5 handles mentioned are
- narendramodi 450447
- BJP4India 166741
- AmitShah 152910
- PMOIndia 84858
- ArvindKejriwal 67572
These handles clearly correspond to the Bhartiya Janata Party and we will treat this cluster as Pro-BJP. If we look at other handles in this cluster from the bar graph we can clearly see the pro-BJP community being represented. This also gives a very good example of why we cannot use the mentions in a twitter status as endorsements. If the graph we constructed earlier was based on mentions instead of retweets, Arvind Kejriwal could’ve easily been part of the Pro-BJP cluster.
- 1 -> This cluster is a bit harder to identify. It contains handles from Indian National Congress as well as the Aam Aadmi party which are major opposition parties to the BJP. It also includes troll accounts and memers like ROFLgandhi which are very popular amongst critics of the current government. One more important thing to notice here is the number of mentions. The difference between the most mentioned users in this cluster and the pro-BJP cluster is drastic. Narendra Modi is mentioned 450447 times which when compared to the most mentioned user in this cluster (Arvind Kejriwal, with 84260 mentions) is almost 5 times. The popularity of this cluster seems to be pretty low compared to the Pro-BJP cluster. I wanted to call this cluster pro-Congress cluster but the high presence of AAP handles in the top 50 makes it impossible. This can be explained easily as the time of gathering data coincided heavily with Delhi Elections
- 3 -> This cluster mostly has Sports-related channels like ESPN etc. The sports handles seem majorly from North America, as can the sports in this cluster
- 6 -> This cluster contains handles from Bollywood actors and Hindi TV series.
- 8 -> This cluster is hard to identify because the handles do not form a homogenous group.
- 14 -> This cluster corresponds to users who are supporters of the Republican party in the USA. But on closer observation, this cluster also includes Pro-Brexit politicians from the UK. The common thread that ties this cluster together seems to be that users in this cluster identify with the political right. There are handles from the left as well but going by the stats we can safely assume these are due to users from the cluster criticizing them.
- 33 -> This cluster has users who talk about film actors and actresses who prominently work in the film industry in Southern India
- 34 -> This cluster has handles from popular football clubs around the world. We can assume the users in the cluster mostly talk or are interested in football
- 35 -> This cluster has handles which are from Pakistan. The top handles are some of the major politicians from Pakistan.
- 43 -> This cluster corresponds to the US Presidential election to happen in 2020. The top handles in this cluster are some of the top contenders from the Democratic and Republican Party
- 44 -> People in this cluster are involved in UK politics as can be seen from the top handles. This cluster also has a lot of News channels which are UK specific
- 47 -> This cluster has handles which are associated with the United Nations and its sub-organizations
- 48 -> Most of the handles mentioned in this cluster are related to Australia and the news agencies there.
- 66 -> The top handles in this cluster are prominent Mexican personalities across multiple areas
- 67 -> This cluster has handles from Spain and handles from Madrid feature prominently in the top handles.
- 73 -> Handles here are from Canada. Politicians and sports teams are among the top handles here.
- 87 -> These handles include mostly artists and illustrators who primarily sketch cartoons. Channels which show cartoons like cartoon network and nickelodeon also feature at the top
- 91 -> This cluster has handles from software industry as well as Technology related handles.
Going by the constituents of the cluster only clusters 0 and 1 seem to be of interest. I must clarify though that this is only because I wanted to do this analysis in the Indian context. If we look closely the cluster 14 is also pretty interesting. The clubbing of right-wing politicians across two separate countries i.e UK and USA seems to suggest that the underlying users are more aligned with political ideology rather than any single political party. Does this also mean that the Indian rightwing is substantially different from the global definition of right-wing? This aspect can be studied further with more focus on analysing the characteristics of the tweets and users in these clusters.
Now that we have finalized the clusters let’s look at the aggregate statistics of each cluster
grouped_df = df[df.cluster.isin([0,1,87])].groupby("cluster")
filtered_clusters = grouped_df.describe()['importance']
sns.barplot(x=filtered_clusters.index,y='count',data=filtered_clusters)
<matplotlib.axes._subplots.AxesSubplot at 0x7f4fa746dc18>
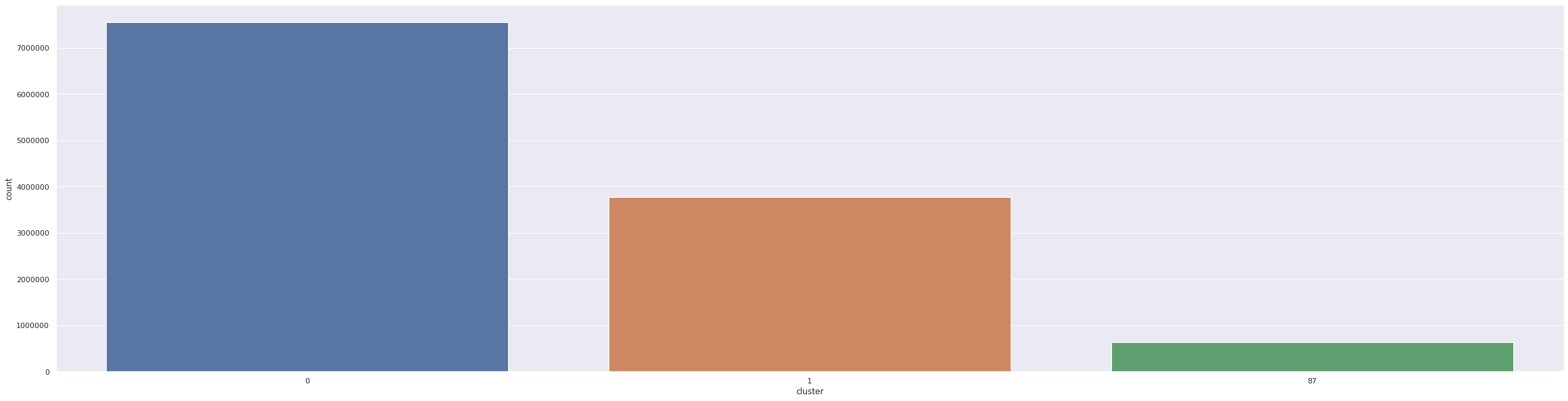
If we see the number of tweets from each cluster we can see that the cluster 0(which is mostly ProBJP cluster) is almost double the size of the cluster 1 (which has AAP and Congress supporters). The importance column here is the weighted degree from the network graph we constructed before, vaguely speaking it represents the importance of any node in the graph. If you check the mean importance both the cluster are pretty close. The 50% column here corresponds to the 50 percentile here which is the same as the median. The median values between these two clusters are also pretty close which when interpreted along with 75 percentile value tells us that these clusters have handles which are fairly similar in importance in the network graph. For contrast, if we see cluster 87, the 25, 50 and 75 percentile scores are very different from the first two clusters. This tells us that the cluster 87 has nodes which are not that important in the graph.
Now that we have the clusters of interest narrowed down we can dig further to analyse the hashtags from each cluster to get a better idea
hashtags_df = grouped_df["hashtags"].apply(__custom_words_accumulator,limit=200)
wc_dict = pd.DataFrame(hashtags_df[0],columns=["handle","freq"])
dct = wc_dict.set_index("handle").to_dict()['freq']
plot_word_cloud(dct)
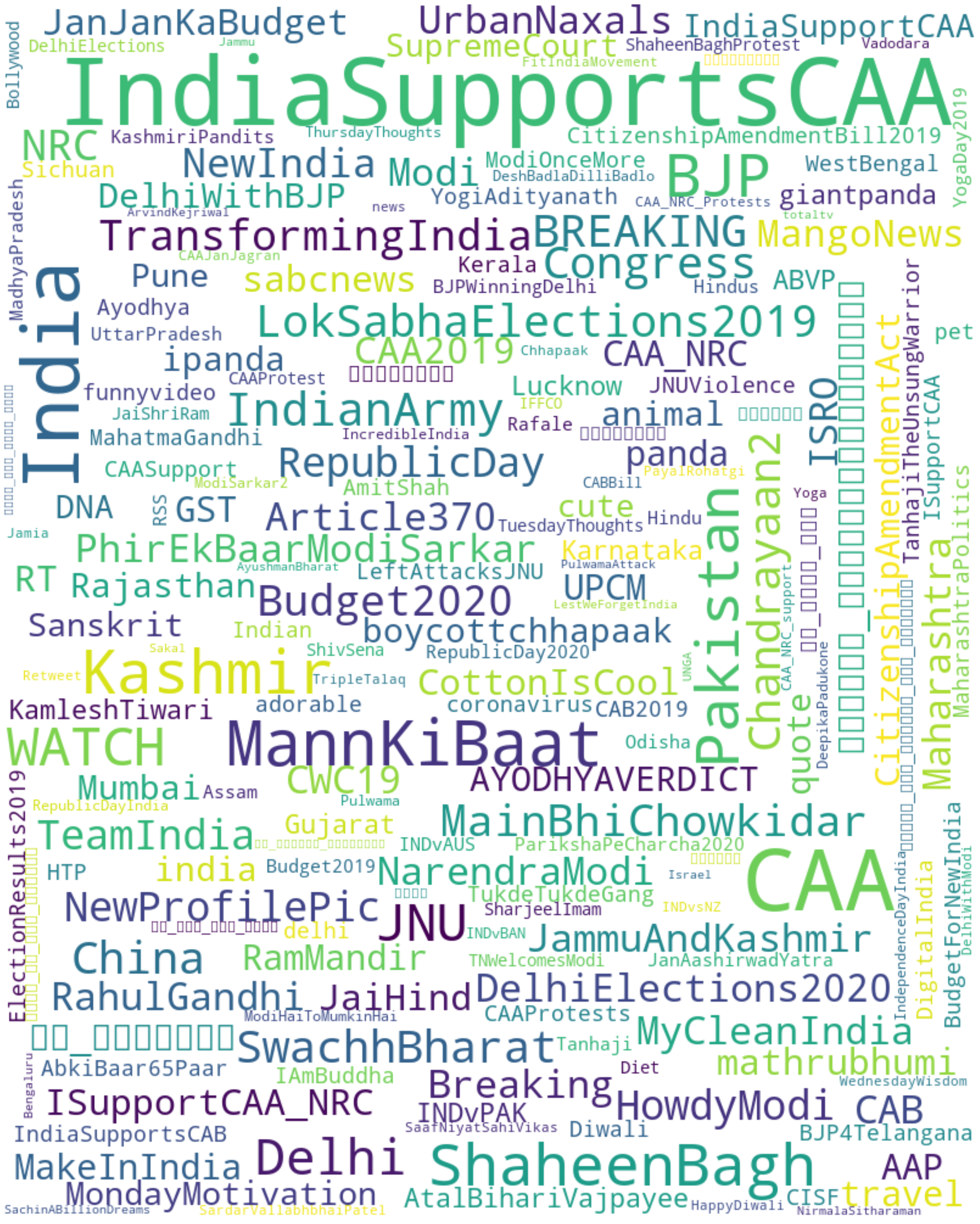
Analyzing community from cluster 0 and the hashtags it becomes clear that this community is overwhelmingly ProBJP. The top hashtags here like IndiaSupportsCAA, MannKiBaat are overwhelmingly talked about by BJP leaders and its supporters.
Similarly, we can see the hashtags used in cluster 1 using WordCloud below
wc_dict = pd.DataFrame(hashtags_df[1],columns=["handle","freq"])
dct = wc_dict.set_index("handle").to_dict()['freq']
plot_word_cloud(dct)

This cluster again seems to support our assumption that this cluster is mostly AntiBJP and supports Congress and AAP. One more observation we can see is that this cluster talks more about BJP than Congress or AAP, can this mean this cluster is more AntiBJP than pro-Congress or AAP?
This cluster also seems very disorganised in the usage of hashtags. If you see the word cloud for cluster 0 almost all the words are of similar size which indicates that they are more or less equal in frequency. Comparing that to this cluster we see there are more hashtags which have high frequency and some hashtags with low frequency. The important thing here is the presence of multiple hashtags for the same event, this means that there is no concerted effort across the cluster to trend certain hashtags. One interesting analysis that can be explored is identifying known BJP leaders and analyzing the response of the community when the leader tweets a particular handle.
Time based Analysis
If you check the code in the below cell you’ll notice I used ddata instead of dataframe. I used a library called dask to apply a counter function to the dataframe we have. The problem with apply() in normal pandas is that it isn’t multithreaded and its’ incredibly slow for large data frames. Dask divides the given dataframe into partitions and applies the function supplied in apply() call parallelly. You can check out dask here and it is one of the leading libraries in python to get your pandas code work efficiently in a multi-threaded scenario.
What we do here is groupby date and in the following cells we groupby different time intervals. The aggregation function counts the number of tweets for a cluster for a time interval. We plot this using seaborn library.
Date
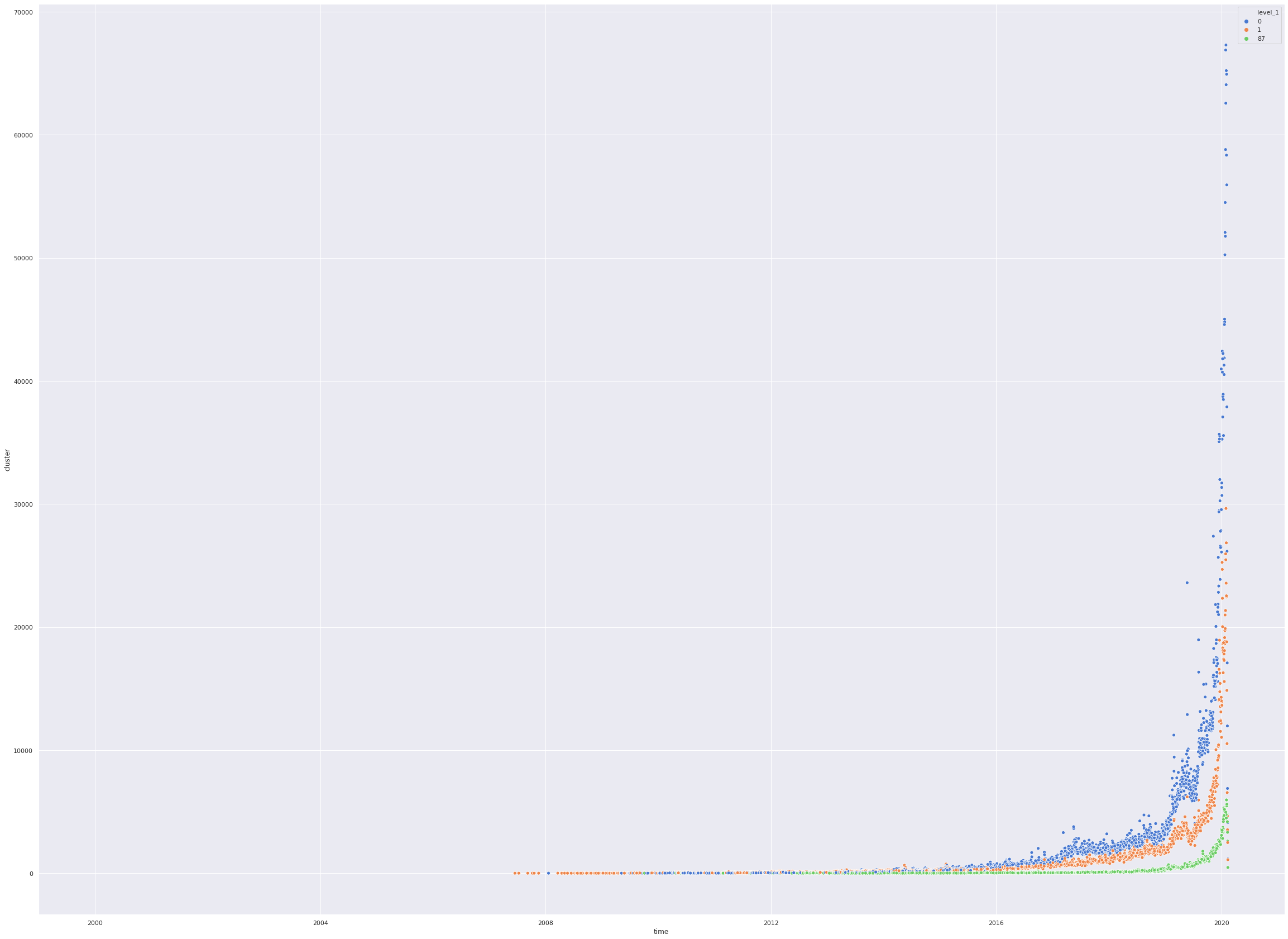
We analyze the tweets based on Dates. The graph below plots number of tweets from each cluster over dates.
- The first cell here lays out the count of tweets for each cluster over dates and the peculiar aspect here is the graphs for all clusters start rising after 2016 mean the handles we have crawled were not as active before 2016 or majority of the handles contributing to our analysis were created after 2016.
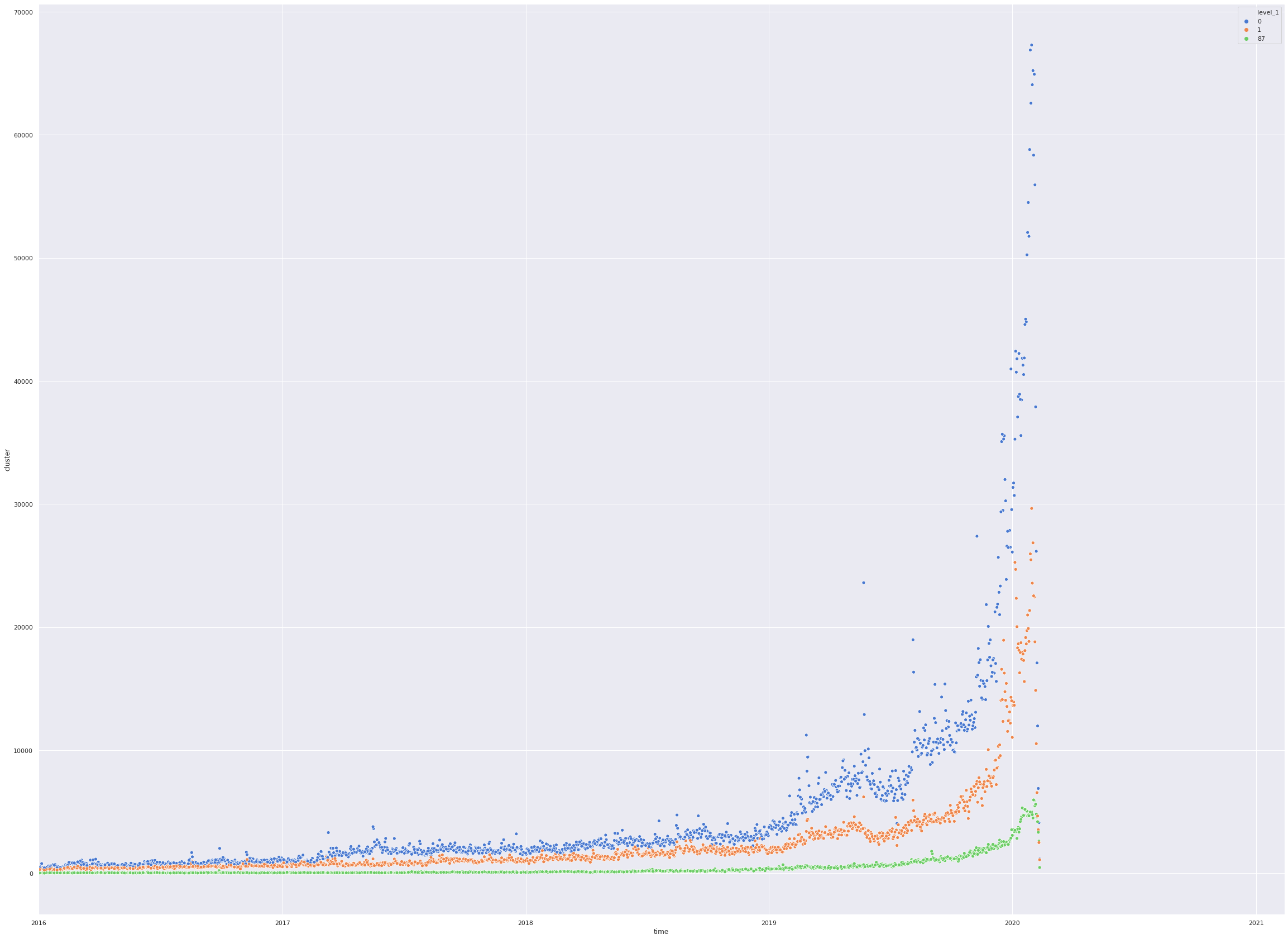
- The next cell we fine-tune our analysis to only after 2016 and analyse the data
def get_cluster_count(series):
c = Counter()
c.update(series.to_list())
return pd.Series(dict(c.most_common()))
def plot_timeseries_data(res, cut_off_date_start=None, cut_off_date_end=None, lineplot=False):
number_of_clusters = len(res.level_1.unique())
sns.set(rc={'figure.figsize': (40,30)})
if lineplot:
sns.lineplot(x="time",hue="level_1",y="cluster",data=res,legend="full",palette=sns.color_palette("muted",number_of_clusters))
else:
sns.scatterplot(x="time",hue="level_1",y="cluster",data=res,legend="full",palette=sns.color_palette("muted",number_of_clusters))
if cut_off_date_start or cut_off_date_end:
plt.xlim(cut_off_date_start, cut_off_date_end)
df = pd.read_pickle("pickles/mention_retweet_hastags_timeobj.pkl")
df = df[df.cluster.isin([0,1,87])]
ddata = dd.from_pandas(df,npartitions=12)
date_grouped_data = ddata.groupby(ddata.time.dt.date)
res = date_grouped_data.cluster.apply(get_cluster_count).compute().reset_index()
plot_timeseries_data(res)
/home/abhishek/Documents/python-env/lib/python3.6/site-packages/ipykernel_launcher.py:22: UserWarning: `meta` is not specified, inferred from partial data. Please provide `meta` if the result is unexpected.
Before: .apply(func)
After: .apply(func, meta={'x': 'f8', 'y': 'f8'}) for dataframe result
or: .apply(func, meta=('x', 'f8')) for series result
/home/abhishek/Documents/python-env/lib/python3.6/site-packages/pandas/plotting/_matplotlib/converter.py:103: FutureWarning: Using an implicitly registered datetime converter for a matplotlib plotting method. The converter was registered by pandas on import. Future versions of pandas will require you to explicitly register matplotlib converters.
To register the converters:
>>> from pandas.plotting import register_matplotlib_converters
>>> register_matplotlib_converters()
warnings.warn(msg, FutureWarning)
import datetime
plot_timeseries_data(res,datetime.date(year=2016,month=1,day=1))
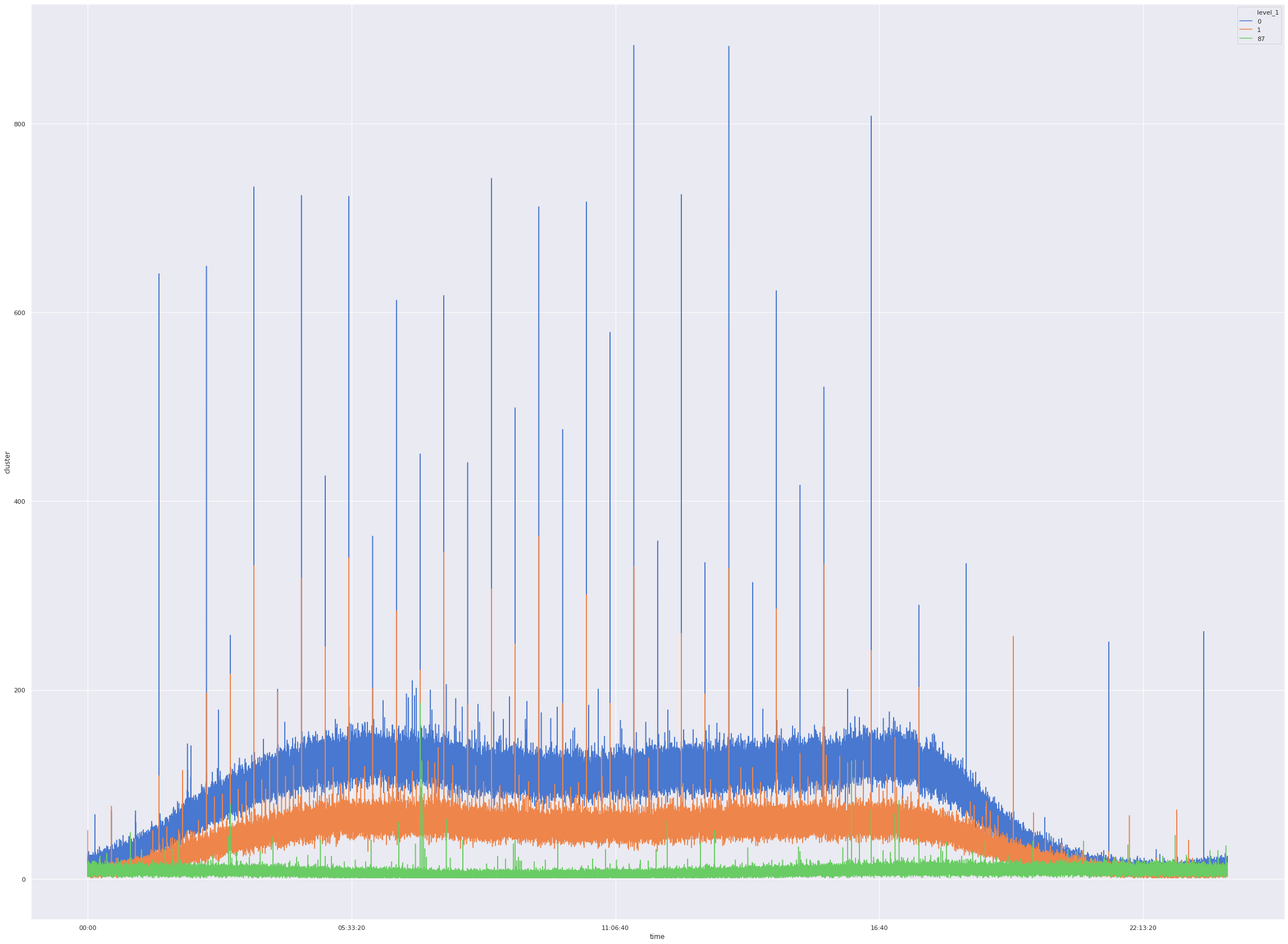
Time of the day analysis
In the next cell we analyse the number of tweets by time of day. Here we can see that all the clusters peak at particular time of day. We’ll analyse this in detail afterwards.
date_grouped_data = ddata.groupby(ddata.time.dt.time)
res = date_grouped_data.cluster.apply(get_cluster_count).compute().reset_index()
plot_timeseries_data(res,lineplot=True)
/home/abhishek/Documents/python-env/lib/python3.6/site-packages/ipykernel_launcher.py:2: UserWarning: `meta` is not specified, inferred from partial data. Please provide `meta` if the result is unexpected.
Before: .apply(func)
After: .apply(func, meta={'x': 'f8', 'y': 'f8'}) for dataframe result
or: .apply(func, meta=('x', 'f8')) for series result
/home/abhishek/Documents/python-env/lib/python3.6/site-packages/IPython/core/pylabtools.py:128: UserWarning: Creating legend with loc="best" can be slow with large amounts of data.
fig.canvas.print_figure(bytes_io, **kw)
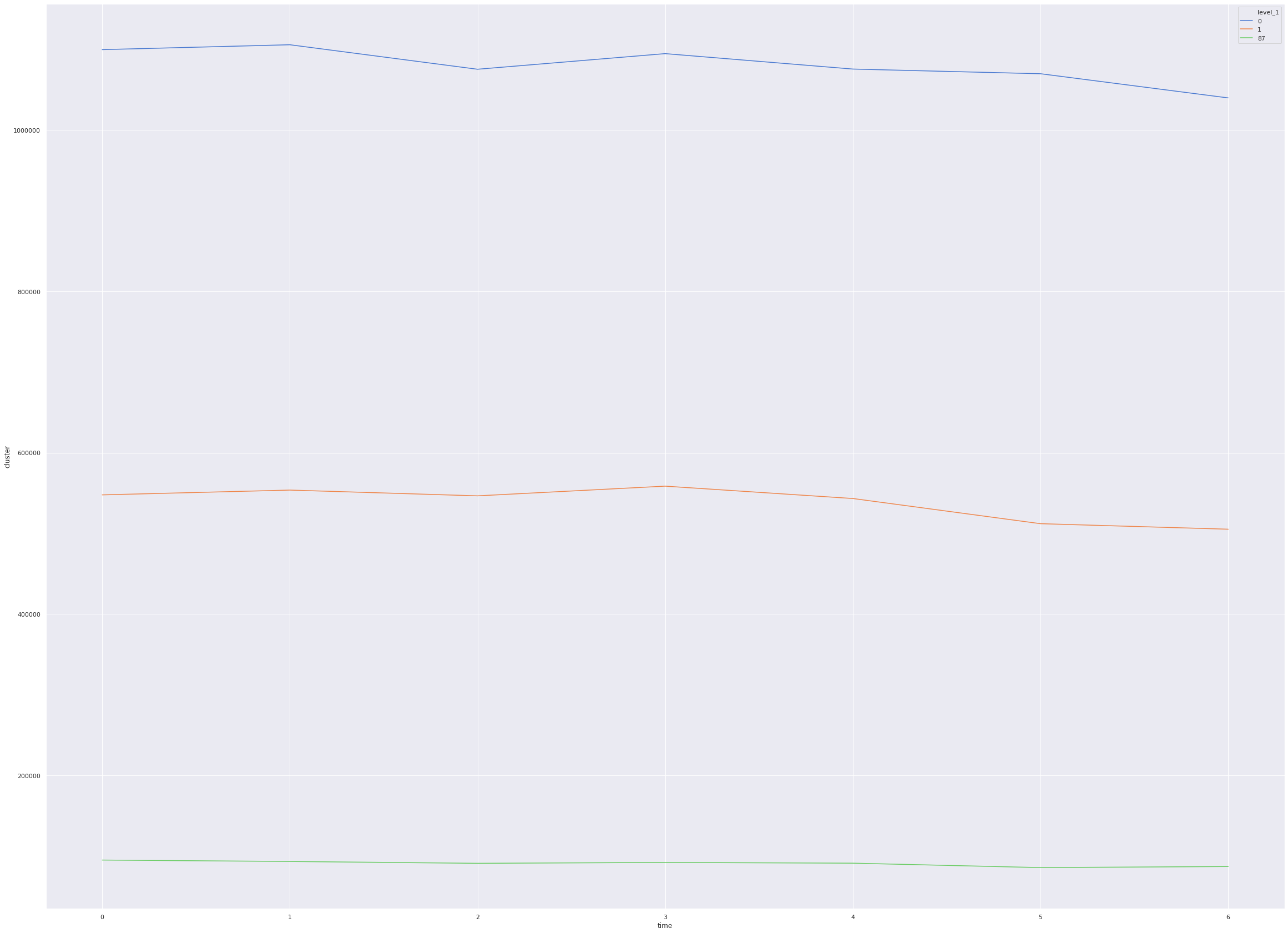
Day of the week analysis
We analyse the number of tweets based on the day of week.
date_grouped_data = ddata.groupby(ddata.time.dt.dayofweek)
res = date_grouped_data.cluster.apply(get_cluster_count).compute().reset_index()
plot_timeseries_data(res,lineplot=True)
/home/abhishek/Documents/python-env/lib/python3.6/site-packages/ipykernel_launcher.py:2: UserWarning: `meta` is not specified, inferred from partial data. Please provide `meta` if the result is unexpected.
Before: .apply(func)
After: .apply(func, meta={'x': 'f8', 'y': 'f8'}) for dataframe result
or: .apply(func, meta=('x', 'f8')) for series result
Hyperlink Analysis
Once we get the data out of database we now analyse the links posted by users from each cluster. Following cell takes care of data cleaning and preprocessing.
- We split the url to only get the hostname of the website and discard the empty urls.
- We remove commonly used links which are irrelevant like facebook, instagram, youtube etc.
- We count the occurances of each website and return a dictionary object.
exclude_list = [
'twitter.com',
'bit.ly',
'www.facebook.com',
'youtu.be',
'www.instagram.com',
'www.youtube.com',
'goo.gl',
'fb.me',
'ow.ly',
'fllwrs.com}\n',
'www.amazon.com',
'instagram.com',
'www.pscp.tv'
]
def get_links_dct(file,topk=None):
links=[]
with open(file) as f:
for row in f:
if row != '{}\n':
links.append(row.split('/')[2].strip().replace('}',''))
c = Counter(links)
dct = dict(c.most_common(topk)) if topk else dict(c.most_common())
for x in exclude_list:
dct.pop(x,None)
return(dct)
def plot_wc_subplots(cluster0,cluster1,fig_size=(50,50)):
wc0 = plot_word_cloud(cluster0,wc_only=True,width=800,color_map="autumn")
wc1= plot_word_cloud(cluster1,wc_only=True,width=800,color_map="winter")
fig = plt.figure(figsize=fig_size)
fig.subplots_adjust(wspace=0)
s1 = fig.add_subplot(121)
s1.axis("off")
s1.imshow(wc0,aspect='auto')
s2 = fig.add_subplot(122)
s2.axis("off")
s2.imshow(wc1,aspect='auto')
fig.show()
cluster0 = get_links_dct('pickles/cluster0.link')
cluster1 = get_links_dct('pickles/cluster1.link')
plot_wc_subplots(cluster0,cluster1,fig_size=(50,25))
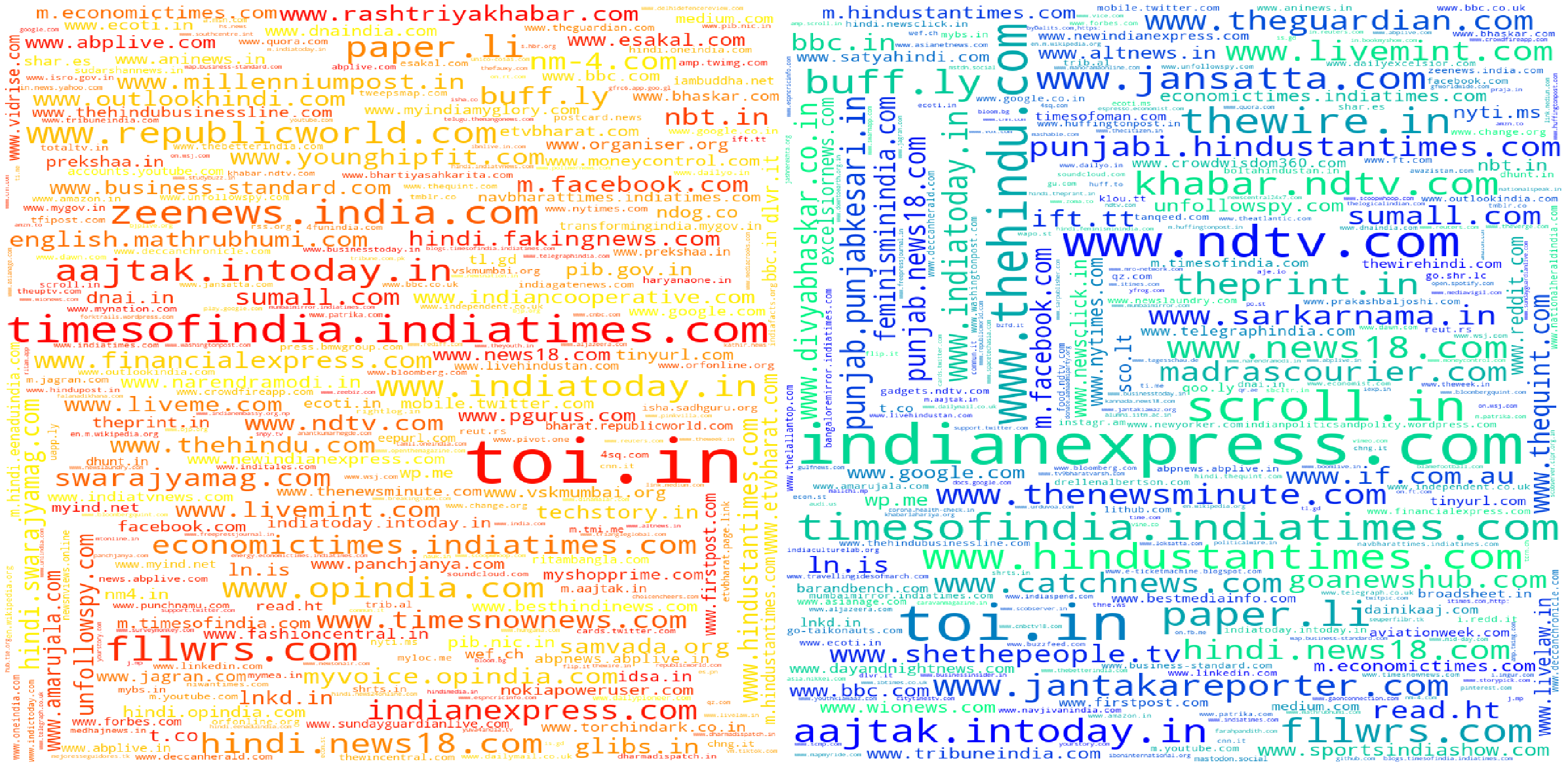
In the previous cell we visualized the links from each cluster in the form of word clouds. We plot them side, cluster0(Pro-BJP) is plotted on the left side whereas the wordcloud on the right side is of the cluster1(Anti-BJP). Some observations after seeing the clusters
- Top sites like indianexpress.com are popular across both clusters.
- www.pscp.tv is among the most popular websites in cluster0. People generally post live recordings of news channels on this platform. This site is mentioned 31927 times in cluster0 compared to 4279 times in cluster1. But comparing between these two numbers is impossible as the size of clusters is different. Instead, We should instead compare the hosts by the percentage of links
- To understand the clusters better we need to identify media sources which are exclusive to that cluster. What we can do is find out the intersection set of both the clusters, this set contains all the sites which are common to both the clusters. Then we do a set difference between the original cluster results and this intersection set to get the sites present only in a particular cluster.
common_links = set(cluster0).intersection(set(cluster1))
for x in common_links:
cluster0.pop(x,None)
cluster1.pop(x,None)
plot_wc_subplots(cluster0,cluster1,fig_size=(50,25))

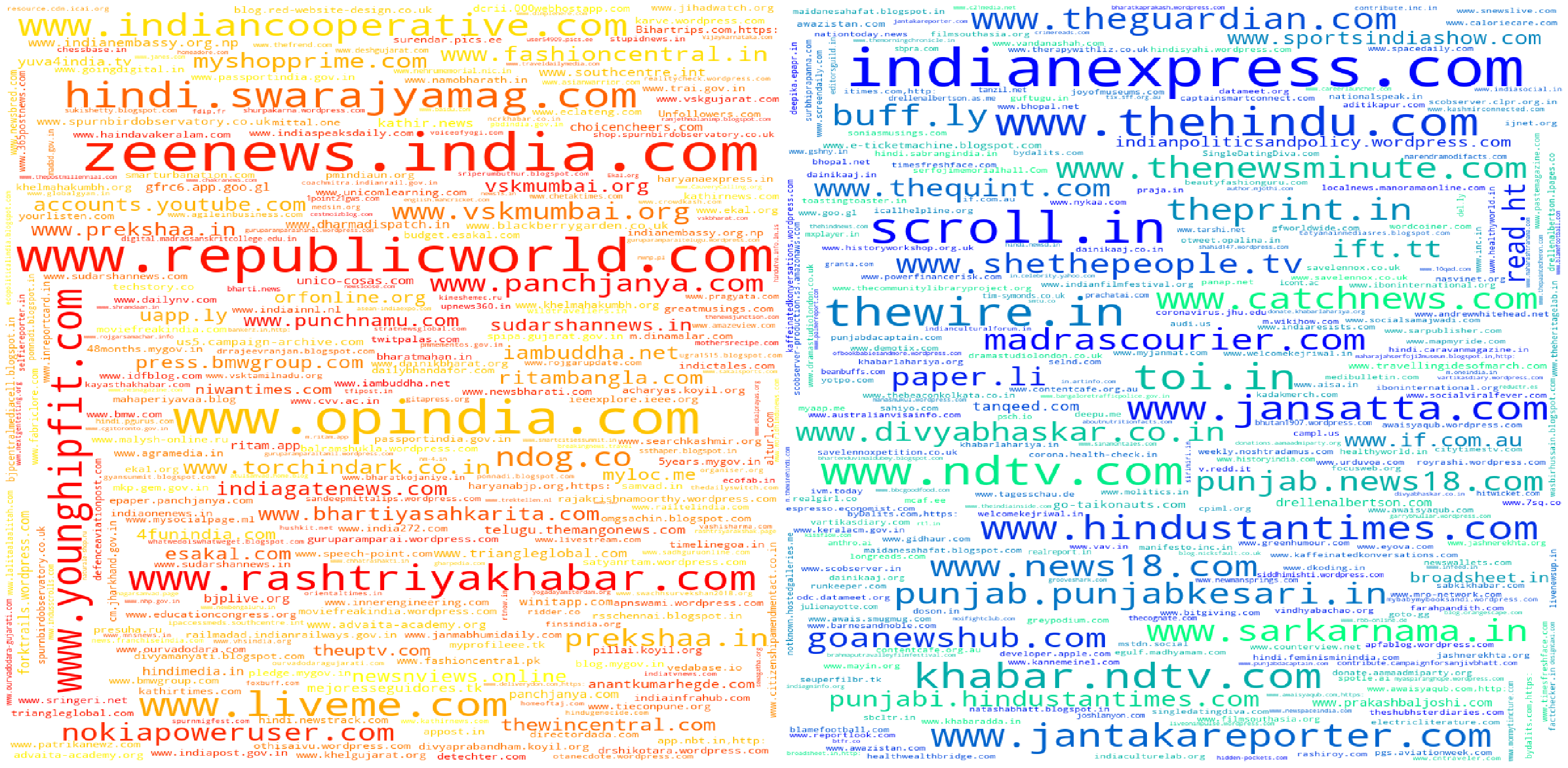
We can see that this approach pushes up less well known sites in both clusters. This approach has another problem though, since we take all the links present in both clusters it pushes up a lot of irrelevant sites into analysis. The other problem I can see is that this approach completely ignores relative ranking of sources within a cluster. For example, if a a site xyz.com occurs as the most frequent site in cluster A but it is say the 100th most frequent site in cluster B it’s removed from both the clusters. This is problematic and doesn’t work.
New approach #1
Instead of removing the common elements completely we come up a different heuristic,
- For each cluster instead of raw counts we maintain proportion of the websites in the dictionary
- Construct an intersection set, taking only the top 100 websites in each cluster. This will take care of the problem where a site mentioned 1000’s of times and only once in a particular cluster being end up in the intersection set.
- Instead of removing all the elements in the intersection set completely we instead re-adjust the ratio of the website in a set by subtracting the ratio of the same website(which is in the interstion set) in other cluster. This returns much better result than the previous methods and since this only takes top 100 websites from each cluster we get more relevant results.
cluster0 = get_links_dct('cluster0.link',100)
cluster1 = get_links_dct('cluster1.link',100)
def get_intersection_balanced_set(cluster0,cluster1):
common_set = set(cluster0).intersection(set(cluster1))
total = sum(cluster0.values())
cluster0 = {k: v / total for k, v in cluster0.items()}
total = sum(cluster1.values())
cluster1 = {k: v / total for k, v in cluster1.items()}
for x in common_set:
cluster0[x] = cluster0[x] - cluster1[x]
cluster1[x] = cluster1[x] - cluster0[x]
if cluster0[x] < 0.01:
cluster0.pop(x,None)
if cluster1[x] < 0.01:
cluster1.pop(x,None)
return cluster0, cluster1
cluster0,cluster1 = get_intersection_balanced_set(cluster0,cluster1)
plot_wc_subplots(cluster0,cluster1,fig_size=(50,25))

New Approach #2
I felt the above heuristic got rid of a lot of superflous websites and limiting the analysis to top 100 websites only would be restrictive. If you see the heuristic it already removes a lot of irrelevant sites by removing all the sites whose proportion in any given cluster is less than 0.01. In the next cell we remove the 100 site limit and run our heuristic again.
cluster0,cluster1 = get_intersection_balanced_set(get_links_dct('cluster0.link'),get_links_dct('cluster1.link'))
plot_wc_subplots(cluster0,cluster1,fig_size=(50,25))
Tweet Analysis (In progress)
In the next part we analyse the tweets sent out from users in both clusters.
This SQL commands pushes all the texts from our dataset into a text file so that we can train a language model with it. The main advantage of this command is this command runs server side so there isn’t any time wasted on moving the data around. This is also more memory efficient since you don’t hold the data in memory, this might become an issue if the table is very large like mine.
COPY (SELECT t.text from tweet_articles_tweepy t JOIN cluster_mapping c ON t.tweet_from = c.id where c.cluster = 0) TO '/media/universe/notebooks/cluster0.txt';
COPY (SELECT t.urls from tweet_articles_tweepy t JOIN cluster_mapping c ON t.tweet_from = c.id where c.cluster = 1) TO '/media/universe/notebooks/cluster1.link';
cluster0=[]
with open('cluster0.txt') as f:
cluster0 = f.read().splitlines()
new_ls=[]
for x in cluster0:
if not x.startswith("RT"):
new_ls.append(x)
len(new_ls)